Feature Engineering
Charpter 2 简单数字的奇特技巧
二值化 0,1
量化或装箱
1 | small_counts |
分位数装箱
1 | ### Map the counts to quartiles |
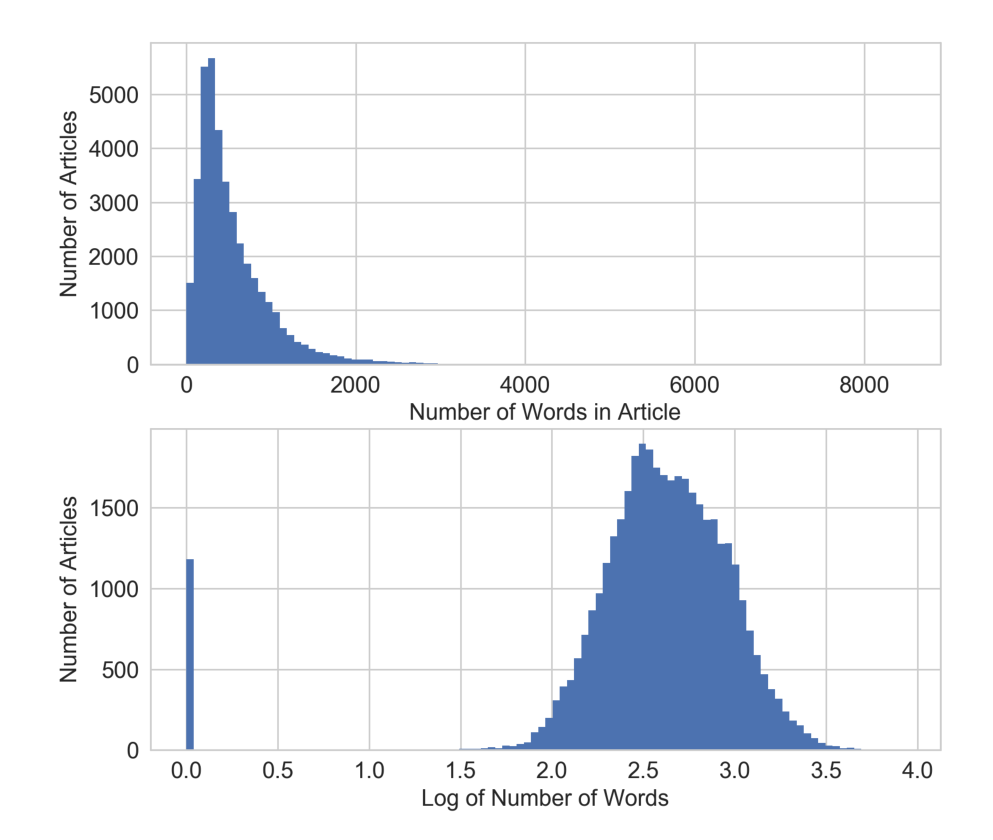
对数转换
线性回归模型的训练过程假定预测误差分布得像高斯,对数变换,这是一种功率变换,将变量的分布接近高斯。
对数变换是处理具有重尾分布的正数的有力工具。(重尾分布在尾部范围内的概率比高斯分布的概率大)
使用$R^2$评分来评估,好的模型有较高的 R 方分数。一个完美的模型得到最高分1, 一个坏的模型可以得到一个任意低的负评分。
1 | scores_log = cross_val_score(m_log, biz_df[['log_review_count']], biz_df['stars'], cv=10) |
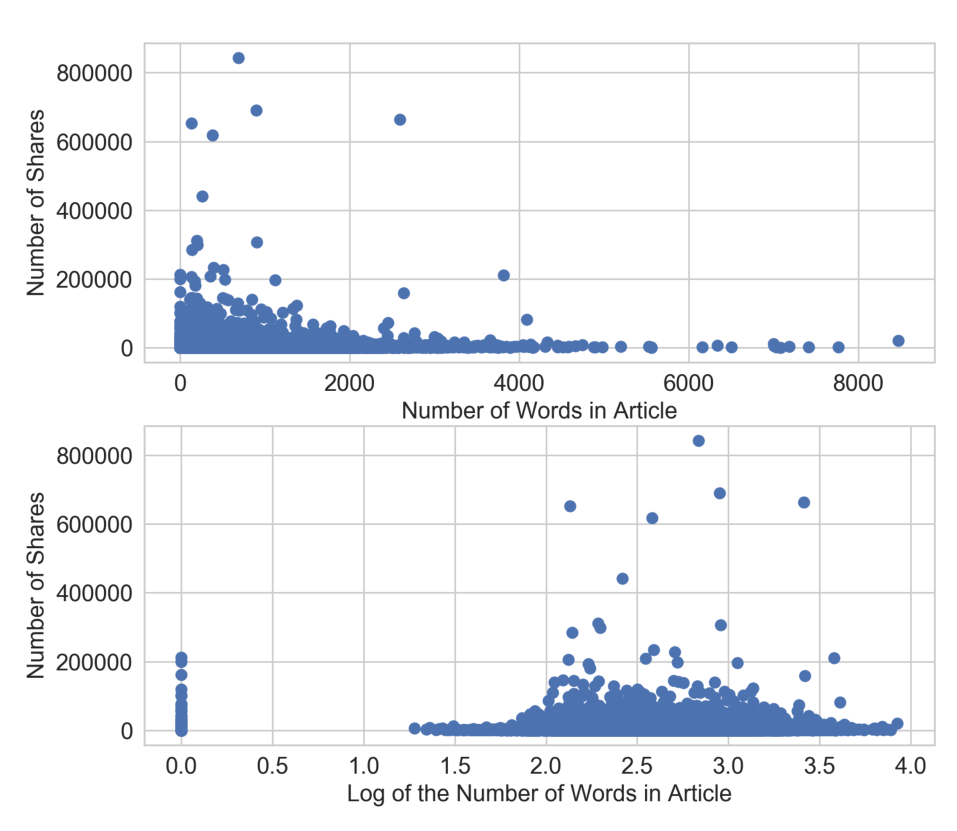
对数变换将较大的离群值压缩到一个更小的范围内
Box-Cox transformation
???
概率图(probplot)是一种直观地比较数据分布与理论分布的简单方法。
特征缩放(Scaling)或归一化(Normalization)
minmaxscaler
$x’=\frac{x-min}{max-min}$
Min-max缩放压缩(或拉伸)所有特征值到[0, 1 ]的范围内

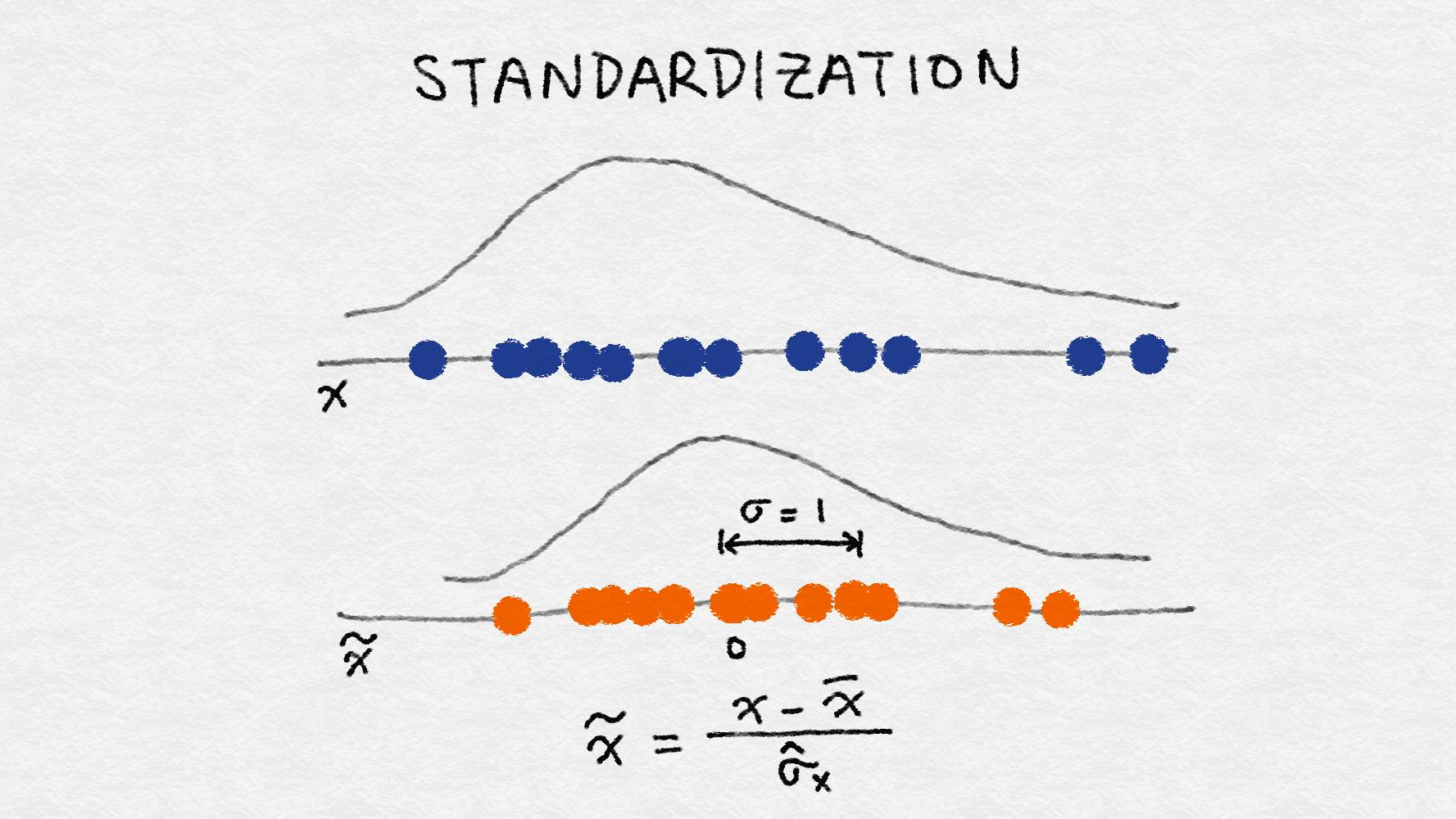
Standardization
$x’=\frac{x-\overline{x}}{\sigma}$
缩放后的特征的平均值为0, 方差为1。如果原始特征具有高斯分布, 则缩放特征为标准高斯
最小最大缩放和标准化都从原始特征值中减去一个数量,将稀疏特征的向量转换为一个稠密的向量。
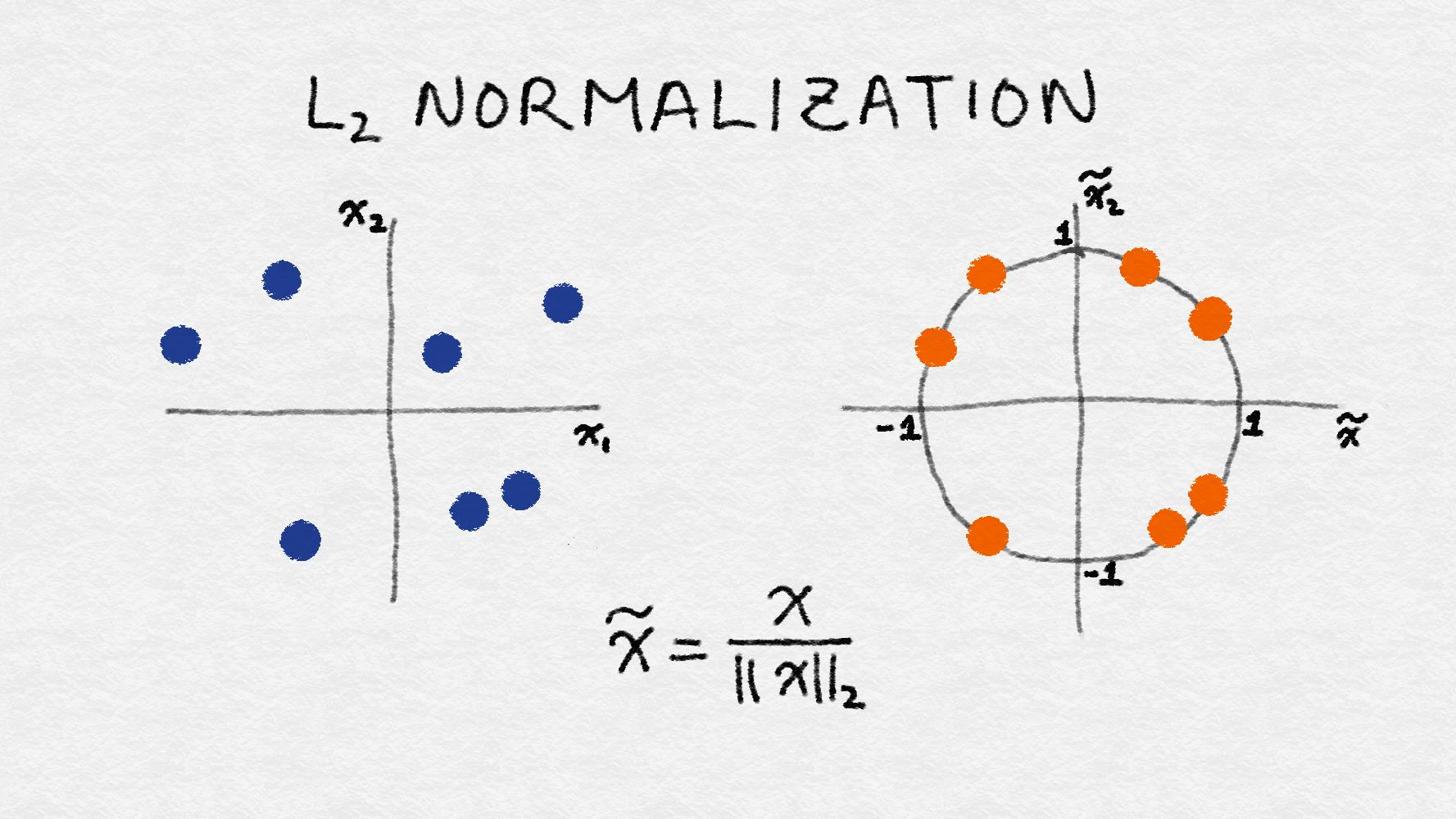
L2 Normalization
$x’=\frac{x}{\sqrt{\sum_{j} x_j^2}}$